

Epistemic Inflation: Stop Minting “Possibilities” Out of Thin Air
If you can say “timeless cause” or “disembodied mind,” that doesn’t make it a live option in a serious inference. Words aren’t lottery tickets for probability. The habit of treating a cool-sounding description as if it were a real, testable possibility is epistemic inflation. It counterfeits probability by sneaking undefined or incoherent ideas into the hypothesis space and then cashing them out as if they earned a share of the prior. The remedy is straightforward: enforce admission rules, budget for the unknowns you haven’t imagined, and apply Bayes without rigging the denominator.
What counts as a real possibility?
Admissibility Norm for any hypothesis 
✓ Coherence: Is specified without contradiction, with clear truth-conditions you could, in principle, check?
✓ Interface: If claims effects in the physical world, is there even a schematic bridge for how it interacts with matter, time, or causation?
✓ Evaluability: Can be constrained by evidence, logic, or probability rather than hide behind mystery?
If a proposal fails these, it doesn’t deserve a slice of 
Reserve space for the unknowns
Do not force all probability mass into the few stories you can currently imagine. Keep an explicit reserve for unimagined mechanisms 


Plain meaning: do not spend your entire probability budget on the hypotheses you can currently name. Reserve a positive chunk
for an “unknowns” option
must be at most
.
✓
: the combined prior you give to each known competitor
.
✓
✓ Why this matters: if, you would quietly exclude future discoveries and make a familiar hypothesis look inevitable simply because you pre-allocated all the mass to what you could name.
Example: if you keep
, then your known hypotheses can sum to at most
. If you currently have three options, you might assign
,
,
, which totals
, leaving
for
That
How epistemic inflation usually happens
◉ CONCEIVABILITY-AS-POSSIBILITY
Imaginability is not admissibility. Being able to picture a “timeless cause” or “disembodied mind” does not earn the claim a seat at the table. A candidate must clear three gates: COHERENCE (no internal contradiction), INTERFACE (at least a thin story for how it touches the observable world), and EVALUABILITY (what would lower its credence). Until then, it does not get a prior. Write it this way so you don’t cheat: 
- ✓ Quick test: list one concrete observation that would count against the claim and one that would count for it—without redefining terms afterward.
◉ POSSIBILITY-BY-STIPULATION
Stipulating “omnipotence makes anything possible” deletes constraints instead of arguing through them. A move that works equally well no matter what we observe explains nothing, so it earns no prior. If every outcome would be counted as a hit, the Bayes factor is neutral: 
- ✓ Key terms: STIPULATION, CONSTRAINTS, UNFALSIFIABLE.
- ✓ Rule: do not replace mechanisms with declarations.
◉ PROMISCUOUS PRIORS
Handing out non-zero priors to any sentence that parses crowds the hypothesis space with fictions. The order is ADMISSIBILITY FIRST, ALLOCATION SECOND. Keep an explicit reserve for unknowns so you don’t starve real competitors: 
- ✓ Key terms: PRIOR INFLATION, HYPOTHESIS CROWDING, UNKNOWN RESERVE.
- ✓ Practice: reject incoherent entries before you start dividing probability mass.
◉ EQUIVOCAL EVIDENCE
Data that fit many stories equally do not move the needle. When rivals expect the evidence to roughly the same degree, the evidence is nondiscriminating: 
- ✓ Key terms: EVIDENTIAL SYMMETRY, NONDISCRIMINATING DATA.
- ✓ Fix: sharpen predictions so one side rates the evidence much higher than the other.
◉ COLLAPSING THE ALTERNATIVE
You inflate support for your favorite by shrinking the complement likelihood. The complement is a mixture of live rivals plus the unknowns bucket: 

- ✓ Key terms: COMPLEMENT LIKELIHOOD, MIXTURE, UNKNOWN BUCKET
- ✓ Guardrail: name real comparators, give them non-zero weights, and keep
Bayes, done cleanly, exposes inflated factors
Posterior odds equal prior odds times a Bayes factor:


◉ Inflation hack 1: minimize the complement likelihood by fiat. If you silently exclude

✓
✓: add up contributions from each specific alternative
✓: how well alternative
✓: how plausible
✓
✓: the share of the evidence explained by those unknown possibilities.
Plain meaning: the chance of the evidence without
◉ Inflation hack 2: treat generic matches as specific predictions. If 
◉ Inflation hack 3: ignore dependence. Re-using the same type of testimony as if it were independent multiplies noise. Correct odds need honest dependence accounting.
Analogies that make the mistake obvious
— Mice vs. Mickey
Droppings in the cupboard are evidence for ordinary mice because that’s the kind of trace real mice reliably leave. Jumping from droppings to Mickey Mouse swaps a plain, well-established category (common mice) for a storybook individual (a trademarked cartoon) that was never shown to be a real-world option. The evidential link is generic; the conclusion you’re drawing is hyper-specific. Until you first establish that “Mickey Mouse” is even a live, real-world candidate, the trace cannot count for him.
✓ What the evidence actually supports: small rodents exist here.
✓ What it does not yet support: a specific, highly embellished character.
✓ How to reason cleanly: upgrade only the minimal hypothesis the evidence directly predicts; add decorations (gloves, red shorts, personality, divinity-like attributes) only when new evidence earns them.
— Perpetual motion pitch
A sketch of a machine that “runs forever” is cheap; a physically possible device is expensive. A drawing does not clear the minimum gates of coherence (no contradictions with conservation laws), interface (clear account of how forces and energy flows work), and evaluability (measurements that would show failure). Treating the sketch as a serious rival before it passes those gates is epistemic inflation.
✓ What’s admissible: a mechanism with stated parts, known interactions, and measurable predictions that could be wrong.
✓ What’s not: “Imagine this clever wheel” with no workable path through known constraints.
✓ Clean rule: a diagram earns attention; only a coherent, testable model earns prior probability.
— The supernatural USB port
Saying “my app talks to another realm through an invisible, untestable interface” names a wish, not a hypothesis. Interfaces, by definition, specify how signals move from one domain to another and what you’d observe on each side when it works or fails. Without even a thin mechanism—inputs, outputs, timings, failure modes, and a protocol that others can probe—you have nothing to evaluate.
✓ Minimal bar for admissibility: specify what the interface takes in, what it emits, under which conditions, and what observation would count as a miss.
✓ Why that matters: if any outcome can be reinterpreted as “it still worked, just mysteriously,” the claim cannot lose and therefore never wins honestly.
✓ Practical takeaway: before you treat a “supernatural connection” as a live competitor, demand a concrete, testable handshake between realms—otherwise keep it out of the hypothesis pool.
Five quick case studies
- Disembodied mind
Every observation ties consciousness to a physical or functional base. Until a coherent account of a substrate-free mind exists, “disembodied mind” isn’t admissible. Do not hand itjust because the phrase parses. Passing a grammar check is not passing the coherence test.
- Hidden yet perfectly loving deity
If perfect love plausibly entails robust availability for relationship, then pervasive hiddenness sits in tension with that property. Unless the compatibility is actually demonstrated, treating it as a settled “possibility” is inflation. You don’t get to waive the conflict away with a label and still claim evidential parity. - Timeless causation and resurrection mechanics
“Outside time” causes “in time” events, and dead tissue is restored with full identity. Before you show how a timeless entity instantiates ordered causal relations and how identity is preserved across total biological failure, you have promissory notes, not hypotheses. - Fine-tuning leap
Cosmic regularities may support a bare creator in the minimal deistic sense, but jumping to a fully specified, doctrine-laden deity smuggles extra content. That’s the Mickey move again: from droppings to a cartoon without evidential payment. - Miracle testimony
Testimony is frequently dependent, error-prone, and incentive-loaded. Treating it as cleanly independent data multiplies likelihoods illegitimately. If you won’t model dependence, you’re minting confirmation out of noise.
Before you say “maybe God did it”…
- ✓ Did you define
- ✓ Do you have a minimal interface sketch for how
- ✓ Can you say what would lower
- ✓ Did you reserve
- ✓ Are you using
- ✓ Are you penalizing vagueness by comparing
The Bayesian skeleton you can actually use
When in doubt, write the comparison explicitly. If you are comparing 
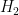
![\frac{P(H_1 \mid E)}{P(H_2 \mid E)} = \frac{P(H_1)}{P(H_2)} \times \frac{P(E \mid H_1)}{P(E \mid H_2)}]](https://s0.wp.com/latex.php?latex=%5Cfrac%7BP%28H_1+%5Cmid+E%29%7D%7BP%28H_2+%5Cmid+E%29%7D+%3D+%5Cfrac%7BP%28H_1%29%7D%7BP%28H_2%29%7D+%5Ctimes+%5Cfrac%7BP%28E+%5Cmid+H_1%29%7D%7BP%28E+%5Cmid+H_2%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
And don’t forget the background complement while assessing the overall plausibility of
![P(E \mid \neg H_1) = \alpha P(E \mid H_2) + \beta P(E \mid U)]](https://s0.wp.com/latex.php?latex=P%28E+%5Cmid+%5Cneg+H_1%29+%3D+%5Calpha+P%28E+%5Cmid+H_2%29+%2B+%5Cbeta+P%28E+%5Cmid+U%29%5D&bg=ffffff&fg=000&s=0&c=20201002)


✓ Meaning: The chance of the evidence when
✓ Weights:
and
. They sum to one because
✓ Why it matters: If you drop
, you make
too small and accidentally inflate support for
✓ Example: If
,
,
, and
, then
.
✓ Takeaway: Always model
If your evaluation of 
Spotting self-sealing claims fast
➘ If redefining a term makes any disconfirming outcome still count, the claim is not evaluable.
When results go the wrong way and the response is to change what the key word means, you’ve moved the goalposts. A testable claim must lock its terms before the test and keep them fixed after. If “healed” meant lower fever within 24 hours, you can’t switch it to “felt spiritually better” once the data arrive. If “prophecy” meant X happening by date Y, it cannot become “a symbolic fulfillment” on date Z. Do this and you’ve guaranteed that nothing can count against the claim, which means nothing can honestly count for it either.
✓ Freeze definitions up front.
✓ Write one outcome that would clearly count against the claim and one that would count for it.
✓ If both outcomes are later reinterpreted as support, the claim is unevaluable by design.
➘ If adding detail never decreases
Real hypotheses trade coverage for commitment. More detail should narrow the outcome space, which normally lowers the prior
✓ Each added detail should create at least one plausible observation that would count against
✓ If every layer is marketed as “compatible with anything,” it is decoration, not prediction.
✓ Watch the tradeoff: tighter
➘ If your story keeps borrowing generic features of the world that all rivals also predict, it isn’t gaining traction.
Citing broad facts like “there is order,” “math works,” or “people have experiences” does not move the needle if rival hypotheses also expect them. In Bayesian terms, when 
✓ Name real comparators and ask what they actually predict about this specific evidence.
✓ Favor contrastive, risky predictions that your rivals would rate much lower, sois meaningfully above 1.
✓ If the “evidence” would have looked the same under your main rivals, it isn’t support; it’s ambience.
Exercises you can try this week
- ✓ Take a popular claim you hear on campus and force it through the admissibility norm. Write exactly what would make you drop
- ✓ Pick a favored explanation and compute a toy Bayes factor against a decent rival, even if you must approximate
. Then add an
- ✓ Rewrite a vague prediction into a sharp one. If the likelihood didn’t change, you probably kept it vague.
- ✓ Ask three friends to independently restate the evidence
. If the statements differ wildly, your likelihoods are fragile.
Mini FAQ
Doesn’t logical possibility guarantee a non-zero prior?
No. Logical possibility is cheap. Admissibility demands coherence with an interface and evaluability criteria. Until then,
Isn’t
It’s the opposite.
But my hypothesis is simple. Doesn’t simplicity win?
Simplicity helps only among admissible rivals with comparable fit to
What if
Then it’s beyond evaluation and shouldn’t be in the pool. You can believe it as poetry if you like, but don’t claim evidential parity.
Quick field guide to honest likelihoods
When you assess
✓ Specificity
Ask whether
✓ Directionality
Good hypotheses stick their necks out: some plausible observations would push their probability down. That is directionality. If every outcome can be spun as support for 
✓ Comparators
Evidence favors 
A sharper look at testimony
Testimony is evidence, but it’s often dependent, filtered, and incentivized. Don’t pretend 
A focus on building models
Draft two columns: admissible and inadmissible. Place candidate hypotheses in one column only after they meet coherence, interface, and evaluability. Then:

Compute both terms honestly, with 
Bottom line
Admitting undefined, incoherent, or unevaluable claims into your hypothesis space is how you mint counterfeit probability. Enforce coherence, interface, and evaluability first. Keep an explicit unknowns reserve

A Deeper Look:



Leave a comment